|
 |
|
||||
|
By
Wikipedia,
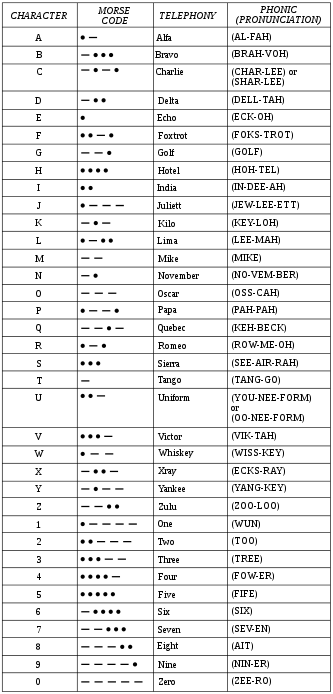
The NATO phonetic alphabet, more formally the international radiotelephony spelling alphabet, is the most widely used spelling alphabet. Though often called "phonetic alphabets", spelling alphabets have no connection to phonetic transcription systems like the International Phonetic Alphabet. Instead, the NATO alphabet assigns code words to the letters of the English alphabet acrophonically (Alfa for A, Bravo for B, etc.) so that critical combinations of letters (and numbers) can be pronounced and understood by those who transmit and receive voice messages by radio or telephone regardless of their native language, especially when the safety of navigation or persons is essential. The paramount reason is to ensure intelligibility of voice signals over radio links. InternationalAdoptionAfter the alphabet was developed by the International Civil Aviation Organization (ICAO) (see history below) it was adopted by many other international and national organizations, including the North Atlantic Treaty Organization (NATO), the International Telecommunication Union (ITU), the International Maritime Organization (IMO), the Federal Aviation Administration (FAA), the American National Standards Institute (ANSI), and the American Radio Relay League (ARRL). It is a subset of the much older International Code of Signals (INTERCO), which originally included visual signals by flags or flashing light, sound signals by whistle, siren, foghorn, or bell, as well as one, two, or three letter codes for many phrases. The same alphabetic code words are used by all agencies, but each agency chooses one of two different sets of numeric code words. NATO uses the regular English numeric words (Zero, One, with some alternative pronunciations), whereas the IMO provides for compound numeric words (Nadazero, Unaone, Bissotwo...). In practice these are very rarely used, as they frequently lead to more confusion between speakers of different languages. NATOThe alphabet's common name (NATO phonetic alphabet) arose because it appears in Allied Tactical Publication ATP-1, Volume II: Allied Maritime Signal and Maneuvering Book used by all allied navies in NATO, which adopted a modified form of the International Code of Signals. Because the latter allows messages to be spelled via flags or Morse code, it naturally called the code words used to spell out messages by voice its "phonetic alphabet". The name NATO phonetic alphabet became widespread because the signals used to facilitate the naval communications and tactics of the United States and NATO have become global. However, ATP-1 is marked NATO Confidential (or the lower NATO Restricted) so it is not publicly available. Nevertheless, a NATO unclassified version of the document is provided to foreign, even hostile, militaries, even though they are not allowed to make it publicly available. The phonetic alphabet is now also defined in other unclassified international military documents. LanguageMost of the words are recognizable by native English speakers because English must be used upon request for communication between an aircraft and a control tower whenever two nations are involved, especially when they have different languages. English is not required domestically, thus if both parties to a radio conversation are from the same country, then another phonetic alphabet of that nation's choice may be used. In most versions of the alphabet, the non-English spellings Alfa and Juliett are found. Alfa is spelled with an f as it is in most European languages. The English and French spelling alpha would not be properly pronounced by speakers of some other languages whose native speakers may not know that ph should be pronounced as f. Juliett is spelled with a tt for native French speakers because they may treat a single final t as silent. In English versions of the alphabet, like that from ANSI or the version used by the British armed forces and emergency services, one or both may revert to their standard English spelling. Alphabet and pronunciation
The pronunciation of the words in the alphabet as well as numbers may vary according to the language habits of the speakers. In order to eliminate wide variations in pronunciation, posters illustrating the pronunciation desired are available from the ICAO. LettersDigitsPronunciationThe spelling and pronunciation given is that officially prescribed by the ICAO, ITU, IMO, and the FAA. The ICAO indicates unstressed numeric syllables in lower case (stressed in UPPER CASE), unlike its own alphabet, where stressed syllables are UNDERLINED UPPER CASE (unstressed in UPPER CASE). In the interests of uniformity, the IMO/FAA style of stressed syllables in BOLD will be used here (underlines might be confused with links). Wherever the agencies (ICAO, ITU, IMO, FAA, ANSI) differ, each agency's preferred pronunciations or spellings are also given in the table. The ICAO, ITU, and IMO give an alternate pronunciation for a couple of letter-words. The FAA gives the alternate pronunciations in one publication as shown by the image on this page, but in other publications it does not. The FAA gives different spellings for their pronunciations depending on the publication consulted. These are from the FAA Flight Services manual (§ 14.1.5) and the ATC manual (§ 2-4-16). ANSI gives English spellings, but does not give pronunciations or numbers. The ICAO, NATO, and FAA use the common English number words (with stress), which are also the second component of the more complex ITU and IMO number words (no stress), but not always pronounced the same. Only the ICAO prescribes any kind of IPA pronunciation (and then only for letters, not numbers). Several of the pronunciations indicated do not occur in current General American English or British Received Pronunciation (ˈʃɑːli, gʌlf, ˈroːmiˑo, ˈuːnifɔrm) or are simplified representations of these (ˈtængo, ˈjænki). The pronunciations indicated are broad transcriptions because many different pronunciations of each code word are allowed in actual use, depending on the language habits of the speakers. Thus only a generic 'e' is indicated, rather than its various shades; 'r' indicates an English r, rather than a trilled r; 'i' indicates either a long or short i. Both the IPA and Latin alphabet pronunciations were developed by the ICAO before 1956 with input from the governments of both the United States and United Kingdom, so the pronunciations of both General American English and British Received Pronunciation are evident, especially in the rhotic and non-rhotic accents. The Latin alphabet version usually has a rhotic accent ('r' always pronounced), as in CHAR LEE, SHAR LEE, NO VEM BER, YOU NEE FORM, and OO NEE FORM, whereas the IPA version usually has a non-rhotic accent ('r' pronounced only before a vowel), as in ˈtʃɑːli, ˈʃɑːli, noˈvembə, and ˈjuːnifɔːm. Exceptions are OSS CAH and ˈuːnifɔrm. The IPA form of Golf implies it is pronounced gulf, which does occur, but not in either General American English or British Received Pronunciation. The Latin alphabet and IPA forms of Bravo have different syllable stresses. The ŋ phoneme ('ng') in the IPA forms of Tango and Yankee is shown as an 'n' and marked [sic]. Furthermore, the pronunciation prescribed for "whiskey" agrees with many (but by no means all) English dialects, in which the "wh-" is simplified into the non-fricative "w-" sound. HistoryThe first internationally recognized alphabet was adopted by the ITU in 1927. The experience gained with that alphabet resulted in several changes being made in 1932 by the ITU. The resulting alphabet was adopted by the International Commission for Air Navigation, the predecessor of the ICAO, and was used in civil aviation until World War II. It continued to be used by the IMO until 1965:
In military use British and American armed forces each developed their phonetic alphabets prior to both forces adopting the NATO alphabet in 1956. British forces adopted the RAF phonetic alphabet which is similar to the phonetic alphabet used by the Royal Navy in World War I. The U.S. adopted the Joint Army/Navy Phonetic Alphabet from 1941 to standardize systems amongst all branches of its armed forces. The U.S. alphabet became known as Able Baker after the words for A and B. The United Kingdom adapted its RAF alphabet in 1943 to be almost identical to the American Joint-Army-Navy (JAN) one. After World War II, with many aircraft and ground personnel drawn from the allied armed forces, "Able Baker" continued to be used in civil aviation. But many sounds were unique to English, so an alternative "Ana Brazil" alphabet was used in Latin America. But the International Air Transport Association (IATA), recognizing the need for a single universal alphabet, presented a draft alphabet to the ICAO in 1947 which had sounds common to English, French, and Spanish. After further study and modification by each approving body, the revised alphabet was implemented on 1 November 1951 in civil aviation, (but it may not have been adopted by any military):
Immediately, problems were found with this list. Some users felt that they were so severe that they reverted to the old "Able Baker" alphabet. To identify the deficiencies of the new alphabet, testing was conducted among speakers from 31 nations, principally by the governments of the United Kingdom and the United States. Confusion among words like Delta, Nectar, Victor, and Extra, or the unintelligibility of other words under poor receiving conditions were the main problems. After much study, only the five words representing the letters C, M, N, U, and X were replaced. The final version given in the table above was implemented by the ICAO on 1 March 1956, and was undoubtedly adopted shortly thereafter by the ITU, because it appears in the 1959 Radio Regulations as an established phonetic alphabet. Because the ITU governs all international radio communications, it was also adopted by all radio operators, whether military, civilian, or amateur (ARRL). It was finally adopted by the IMO in 1965. In 1947 the ITU adopted the compound number words (Nadazero Unaone, etc.), later adopted by the IMO in 1965. UsageThe alphabet is used to spell out parts of a message containing letters and numbers to avoid confusion, because many letters sound similar, for instance "n" and "m" or "b" and "d". For instance the message "proceed to map grid DH98" could be transmitted as "proceed to map grid Delta-Hotel-Niner-Ait". Using "Delta" instead of "D" avoids confusion between "BH98" and "DH98". The unusual pronunciation of certain numbers was designed to reduce confusion, eg, "Fife" instead of "Five" to avoid confusion with "Fire". In addition to the traditional military usage, civilian industry uses the alphabet to combat similar problems in the transmission of messages over telephone systems. For example, it is often used in the retail industry where customer or site details are spoken over the telephone (in order to authorize a credit agreement or confirming stock codes), although ad hoc coding is often used in that instance. It has found heavy usage in the information technology industry to accurately and quickly communicate serial/reference codes (which can be and frequently are extremely long) or other specialised information by voice. In addition, most major airlines use the alphabet to communicate passenger name records (PNRs) internally, and in some cases, with customers. Several letter codes and abbreviations using the phonetic alphabet have become well-known, such as Bravo Zulu (letter code BZ) for "well done", Checkpoint Charlie (Checkpoint C) in Berlin, and Zulu Time for Greenwich Mean Time or Coordinated Universal Time. During the Vietnam War, Viet Cong guerrillas and the group itself were referred to as VC, or Victor Charlie; the name "Charlie" became synonymous with this force. In recent years "Charlie" has become viewed as a racist term when used in relation to the Vietnamese. VariantsAviation
OtherMany unofficial phonetic alphabets are in use that are not based on a standard, but are based on words the transmitter can easily remember. Often, such ad-hoc phonetic alphabets are first name alphabets based on (mostly) men's names, such as Alan Bobby Charlie David Edward Frederick George Howard Isaac James Kevin Larry Michael Nicholas Oscar Peter Quincy Robert Stephen Trevor Ulysses Vincent William Xavier Yaakov Zebedee, or on a mixture of names and other easily recognizable (and locally understandable) proper nouns, such as U.S. states, local cities and towns, etc. One documented example of this is the LAPD phonetic alphabet. Additions in other languagesCertain languages' standard alphabets have letters, or letters with diacritics e.g. umlauts, that do not exist in the English alphabet. Each of their countries has had its own radiotelephonic alphabet containing words for these letters decades before the ICAO had their alphabet. DanishThe Danish phonetic alphabet uses Ægir for <Æ>, Ødis (village and parish in Denmark) for <Ø>, and Åse (female first name) for <Å>. EstonianIn Estonian, Õnne (female first name) is used for <Õ>, Ärni (male first name) is used for <Ä>, Ööbik ("Nightingale") for <Ö> and Ülle (female first name) for <Ü>. FinnishIn Finnish, Åke (male first name) is used for <Å>, Äiti ("mother") for <Ä> and Öljy ("oil") for <Ö>. GermanTo the above NATO series has been added Ärger ("anger") for <Ä>, Ökonom ("economist") for <Ö>, and Übermut ("high spirit") for <Ü>. These additions are not in the ICAO alphabet and are used only in the German-speaking world. Three other special consonants commonly used in German radiotelephonic alphabets are: Charlotte for <Ch>, Schule ("school") for <Sch>, and Esszett for <ß>. ß can be also be encoded as "ss". NorwegianThe Norwegian phonetic alphabet of the Norwegian Defence Forces uses Ærlig ("honest") for <Æ>, Østen ("the East") for <Ø>, and Åse (female first name) for <Å>. The civil alphabet uses Ægir (a Norse god), Ørnulf (a male name) and Ågot (a female name). SpanishIn Spain, Ñoño is used for <Ñ>. SwedishIn Swedish, Alfa Alfa is used for <Å>, Alfa Echo for <Ä> and Oscar Echo <Ö> when using the NATO phonetic alphabet. See alsoExternal links
Text from Wikipedia is available under the Creative Commons Attribution/Share-Alike License; additional terms may apply.
Published in July 2009. Click here to read more articles related to aviation and space!
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||

 |
|
Copyright 2004-2026 © by Airports-Worldwide.com, Vyshenskoho st. 36, Lviv 79010, Ukraine Legal Disclaimer |